Mini-batching with in-memory datasets
Intro
When doing research and quickly trying out ideas, speed is important. Waiting a long time until an experiment completes may keep us idle, and reduce our efficiency as researchers. Quick feedback from our experiments is typically crucial to keep our productivity, and this post may help us do exactly that - be more productive by quickly iterating experiments.
When reading typical tutorials about training models with PyTorch from datasets stored in PyTorch tensors, we see this pattern:
from torch.utils.data import TensorDataset, DataLoader
ds = TensorDataset(X, y)
for Xb, yb in DataLoader(ds, batch_size=..., shuffle=...):
# inner training loop code: forward, backward, optimizer update, ...
However, when the training loop code is fast, such as when we’re training a small model, this pattern might not be a good idea in practice. Why? Well, DataLoader, as its name suggests, is optimized for data loading. It has plenty of logic for handling loading, collating, and batching data in a generic and parallel manner. And it does a pretty good job - these features are important for many applications. However, when the data fits in memory, and models are fast to compute, this overhead is quite significant. And even more so - when the data and model fit in GPU memory! This is oftentimes the case when we want to experiment with some idea on a small scale, before trying it out on a larger scale.
This post is devoted to demonstrating this overhead, and presenting an alternative that is easy to use and is fast. As usual, the code for this post is in this notebook you can deploy on Colab, and the utilities we develop are in this gist. The examples, however, are assumed to be run in a notebook, since we use the %%time magic keyword to measure running times. Moreover, the post assumes we have access to an GPU with at least 1GB of memory. I ran it on Colab with a T4 GPU.
I know typical posts on this blog are mathematically inclined, but not this one. This one is purely about coding, so let’s get started!
**Update**
The utilities developed in this post were converted to a small Python library you can install with
pip install batch-iter
The source code is in this GitHub repo.
DataLoader overhead
Let’s try to measure the overhead of the DataLoader class first, before trying to solve it. To that end, let’s generate a data-set for a nonlinear problem:
import torch
device = torch.device('cuda:0')
n_features = 1000
n_samples = 500000
X = torch.randn(n_samples, n_features, device=device)
y = torch.randn(n_samples, device=device)
Note, that the labels are completely random, since we don’t aim to actually learn anything. Our aim is only benchmarking the running times of our training code.
Now let’s define a network to learn it:
from torch import nn
def make_network():
return nn.Sequential(
nn.Linear(n_features, n_features // 2),
nn.ReLU(),
nn.Linear(n_features // 2, n_features // 8),
nn.ReLU(),
nn.Linear(n_features // 8, 1)
)
Now let’s train it, and measure the time it takes:
net = make_network().to(device)
optim = torch.optim.SGD(net.parameters(), lr=1e-3)
criterion = nn.MSELoss()
ds = torch.utils.data.TensorDataset(X, y)
%%time
for Xb, yb in torch.utils.data.DataLoader(ds, batch_size=64, shuffle=True):
loss = criterion(net(Xb).squeeze(), yb)
loss.backward()
optim.step()
optim.zero_grad()
I got the following output:
CPU times: user 12.8 s, sys: 293 ms, total: 13.1 s
Wall time: 13.4 s
How much of it is the DataLoader’s work? Let’s replace the training loop with pass and see what happens:
%%time
for Xb, yb in torch.utils.data.DataLoader(ds, batch_size=64, shuffle=True):
pass
The output is:
CPU times: user 4.13 s, sys: 19 ms, total: 4.15 s
Wall time: 4.15 s
Whoa! Approximately 30% of the time is spent by just iterating over the data! Now let’s try to do something about it. These four seconds don’t sound like much, but we have several training epochs. And probably some hyperparameter tuning cycles. Multiply these four seconds by the number of epochs and then by the number of hyperparameter configurations, and you will find yourself wasting plenty of time! So let’s try to be more productive for small-scale experiments.
Manual batch iteration
Typically, we want to iterate over batches from a set of tensors. In most cases, this set is of size two - the features tensor, and the labels tensor. But sometimes we want more, and that’s why TensorDataset also accepts a set of arbitrary size.
Iterating over a set of tensors is quite easy with PyTorch. We just need to be careful about not copying data from CPU to GPU and vice versa, so we need to make sure that everything is one the same device. So here is the function - it accepts an array of tensors, checks which device they’re on, creates a list of indices on the device, and uses those to iterate over mini-batches:
def iter_tensors(*tensors, batch_size):
device = tensors[0].device # we assume all tensors are on the same device
n = tensors[0].size(0)
idxs = torch.arange(n, device=device).split(batch_size)
for batch_idxs in idxs:
yield tuple((x[batch_idxs, ...] for x in tensors))
Well, let’s try it out:
%%time
for Xb, yb in iter_tensors(X, y, batch_size=64):
pass
CPU times: user 222 ms, sys: 925 µs, total: 223 ms
Wall time: 225 ms
Ah, much better! But this code does not support shuffling, so let’s add it using the torch.randperm() function:
def iter_tensors_with_shuffle(*tensors, batch_size, shuffle=False):
device = tensors[0].device # we assume all tensors are on the same device
n = tensors[0].size(0)
if shuffle:
idxs = torch.arange(n, device=device)
else:
idxs = torch.randperm(n, device=device)
idxs = idxs.split(batch_size)
for batch_idxs in idxs:
yield tuple((x[batch_idxs, ...] for x in tensors))
And let’s try it out:
%%time
for Xb, yb in iter_tensors_with_shuffle(X, y, batch_size=64, shuffle=True):
pass
CPU times: user 226 ms, sys: 2.86 ms, total: 229 ms
Wall time: 231 ms
Well, pretty fast. Still much better than the 4.8 seconds with DataLoader.
And now for one more enhancement. In many cases we like to use the tqdm library when iterating over data. However, we need to know the amount of items we’re iterating over. Unfortunately, Python generators used in our functions above don’t provide the __len()__ method required. So let’s refactor our code into a class that has the required methods:
class BatchIter:
def __init__(self, *tensors, batch_size, shuffle=True):
"""
tensors: feature tensors (each with shape: num_samples x *)
batch_size: int
shuffle: bool (default: True) whether to iterate over randomly shuffled samples.
"""
self.tensors = tensors
device = tensors[0].device
n = tensors[0].size(0)
if shuffle:
idxs = torch.randperm(n, device=device)
else:
idxs = torch.arange(n, device=device)
self.idxs = idxs.split(batch_size)
def __len__(self):
return len(self.idxs)
def __iter__(self):
tensors = self.tensors
for batch_idxs in self.idxs:
yield tuple((x[batch_idxs, ...] for x in tensors))
Now let’s try it out:
from tqdm.auto import tqdm
%%time
for Xb, yb in BatchIter(X, y, batch_size=64, shuffle=True):
pass
100%|██████████| 7813/7813 [00:00<00:00, 36521.03it/s]
CPU times: user 249 ms, sys: 1.88 ms, total: 251 ms
Wall time: 254 ms
Beautiful! We have built a small utility class that I called BatchIter to eliminate most of the overhead of DataLoader in simple cases, when all data is in-memory, and models are small and lean. I hope it is useful to your small experiments. But now let’s extend it.
Iterating over grouped data
There are applications where we want to iterate over mini-batches composed of groups of samples. One such case is the learning to rank problem: we are given a query and a corresponding list of candidate answers, each labeled with a score designating its relevance. Our objective is learning a function that scores items for a given query, such that more relevant items have a higher score. Methods that define a loss for the entire list of suggestions for a given query, known as list-wise methods, require all suggestions belonging to the same query to be grouped together.
Here, will built a utility class for iterating over grouped samples. We assume that the input consists of samples, each having a _group id, and that each group appears consecutively. The shuffling process shuffles entire groups, rather than individual samples. This is illustrated below - we have a group-id, and \(n\) tensors \(T_1, \dots, T_n\) that comprise our dataset:
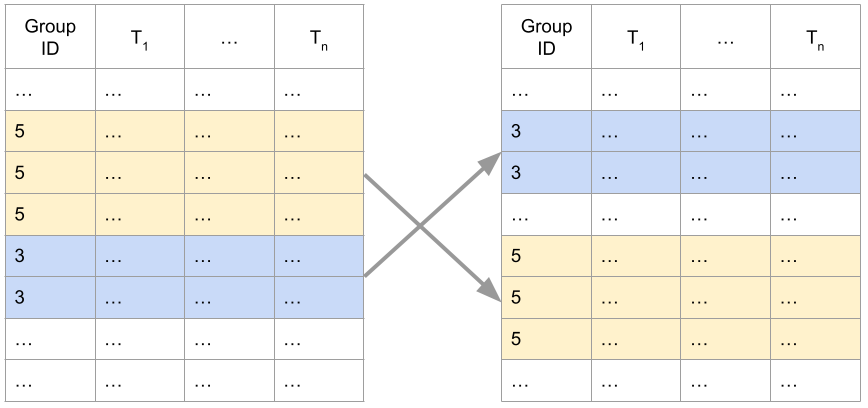
Similarly, our utility assumes that the mini-batch size specifies the number of groups in each mini-batch, rather than the number of samples. This plays nicely with list-wise learning to rank, since each group produces one loss value for the entire group. Therefore, with a mini-batch of \(k\) groups, we shall have a sample of \(k\) losses.
Group shuffling
To shuffle entire batches, we need several utilities. Our main requirement for these utilities is that they are composed of primitive vectorized PyTorch functions, so that we can run them on the GPU as well. The first one is called lexical sort, and it does what you think it does - it returns the permutation for sorting several tensors in lexicographical order. There is a similar function in NumPy, called lexsort, and we shall implement our own for PyTorch. Fortunately, we don’t need to think too much about it - the developers of the PyTorch-Geometric1 library already wrote one, so the implementation below is just a simplified version:
def lexsort(*keys, dim=-1):
if len(keys) == 0:
raise ValueError(f"Must have at least 1 key, but {len(keys)=}.")
idx = keys[0].argsort(dim=dim, stable=True)
for k in keys[1:]:
idx = idx.gather(dim, k.gather(dim, idx).argsort(dim=dim, stable=True))
return idx
It does what we would expect it to do - it computes the sorting order by each tensor separately using a stable sorting algorithm. It uses the PyTorch gather functions for reshuffling. Let’s see how it works - we shall sort the pairs \((5, 4), (3, 1), (5, 1), (3, 3), (5, 3), (5, 2), (3, 2)\) in lexicographic order - meaning, we compare by the first item of each pair, and among the pairs with equal first item, we compare by the second item. Conforming to the same convention as NumPy, we specify the tensors in reverse order, namely, first the tensor with the second components, and then the tensor with the first components, as below:
first = torch.tensor([5, 3, 5, 3, 5, 5, 3])
second = torch.tensor([4, 1, 1, 3, 3, 2, 2])
order = lexsort(second, first)
print(first[order], second[order])
tensor([3, 3, 3, 5, 5, 5, 5]) tensor([1, 2, 3, 1, 2, 3, 4])
Why is it useful? One simple way of shuffling entire groups is sorting by a hash code of the query id, and break ties by the query id itself. Tie braking is required due to hash collisions. Speaking of the devil, we will also need a function for component-wise hash codes in PyTorch, so I wrote my own which implements the FNV hash algorithm:
def fnv_hash(tensor):
"""
Computes the FNV hash for each component of a PyTorch tensor of integers.
Args:
tensor: A PyTorch tensor of type int32 or int16
Returns:
A PyTorch tensor of the same size and dtype as the input tensor, containing the FNV hash for each element.
"""
# Define the FNV prime and offset basis
FNV_PRIME = torch.tensor(0x01000193, dtype=torch.int32)
FNV_OFFSET = torch.tensor(0x811c9dc5, dtype=torch.int32)
# Initialize the hash value with zeros (same size and dtype as tensor)
hash_value = torch.full_like(tensor, FNV_OFFSET)
for byte in split_int_to_bytes(tensor):
hash_value = torch.bitwise_xor(hash_value * FNV_PRIME, byte)
# No need to reshape, output already has the same size and dtype as input
return hash_value
Now we can obtain permutation indices that permute entire groups with a given seed, simply by sorting by the pairs (hash(group_id + seed), group_id). Here is an example:
group_id = torch.tensor([5, 5, 8, 8, 8, 8, 1, 1])
seed = 1
order = lexsort(group_id, fnv_hash(group_id + seed))
print(group_id[order])
tensor([5, 5, 1, 1, 8, 8, 8, 8])
Let’s try another seed:
seed = 2
order = lexsort(group_id, fnv_hash(group_id + seed))
print(group_id[order])
tensor([1, 1, 8, 8, 8, 8, 5, 5])
Note, that both lexsort and fnv_hash are composed of vectorized PyTorch functions, as desired. The only loop is in the fnv_hash function, that loops over the element bytes. For example, when computing a hash of an int32 tensor where each element has four bytes, the loop will have four iterations.
It appears that the shuffling problem has been addressed.Our next challenge is addressing the batching problem - how do we iterate over mini-batches of groups.
Mini-batches of groups
Suppose we have a group_id tensor that has been permuted using our shuffling code. Now we need to somehow divide it into mini-batches of groups. As with the previous challenge, we would like the code to be composed of vectorized PyTorch primitives, so that it is GPU friendly and fast.
Our first utility function is simple - it computes the start indices of the groups. For example, in the group-id tensor [8, 8, 8, 1, 1, 7, 7, 7, 7], we have three groups: the first begins at index 0, the second at index 3, and the last one at index 5. For convenience, we have an additional “empty” group after the end of the tensor, which is by definition after the last element, at index 9. The reason why it is convenient will be apparent soon.
Such indices are pretty straightforward to compute using the torch.unique_consecutive function, that returns the unique consecutive elements, and optionlally their counts. The cumulative sum of the counts gives the indices of all, but the first group. The first group, by definition, is at index 0, and this is achieved by padding. So here is the function:
def group_idx(group_id):
values, counts = group_id.unique_consecutive(return_counts=True)
idx = torch.cumsum(counts, dim=-1)
return torch.nn.functional.pad(idx, (1, 0))
Let’s test it:
group_id = torch.tensor([8, 8, 8, 1, 1, 7, 7, 7, 7])
indices = group_idx(group_id)
print(indices)
tensor([0, 3, 5, 9])
How does it help us? Well, suppose we want mini-batches of size two. The first mini-batch will be from sample 0 to sample 5. The next one, will be from sample 5 to sample 9. Indeed, group_id[0:5] is the tensor of [8, 8, 8, 1, 1], containing two groups, and group_id[5:9] is the tensor of [7, 7, 7], which is the last remaining groups.
So let’s write a function that takes the result of group_idx as its input, and produces the start and end indices of each mini-batch. Suppose our batch size is 5. So it looks simple - just take items group_idx[0], group_idx[5], group_idx[10], ... for the start indices, and group_idx[5], group_idx[10], group_idx[15], ... for the end indicates, right? Well, almost. There are certain special cases we need to take care of. First, what if we have less groups than our batch size? And second, what if the number of groups is not divisible by the batch size? In that case, would exclude the last batch. To make sure our code is correct, we will use the simple trick of padding, and make sure that the number of elements is divisible by the batch size. It’s easy to see that it solves both special cases. So here is the function:
def batch_endpoint_indices(group_idx, batch_size):
padding = batch_size - (len(group_idx) - batch_size * (len(group_idx) // batch_size))
group_idx = torch.nn.functional.pad(group_idx, (0, padding), mode='replicate')
start_points = group_idx[0:-1:batch_size]
end_points = group_idx[batch_size::batch_size]
return start_points, end_points
Let’s try it out with our example:
group_id = torch.tensor([8, 8, 8, 1, 1, 7, 7, 7, 7])
from_idx, to_idx = batch_endpoint_indices(group_idx(group_id), batch_size=2)
for start, end in zip(from_idx, to_idx):
print(start, end)
0 5
5 9
As expected, 0 to 5, and 5 to 9. What if the we try mini-batches of size 3?
group_id = torch.tensor([8, 8, 8, 1, 1, 7, 7, 7, 7])
from_idx, to_idx = batch_endpoint_indices(group_idx(group_id), batch_size=2)
for start, end in zip(from_idx, to_idx):
print(start, end)
0 9
As expected, one mini-batch, from 0 to 9. All three groups inside. So now we can put our utilities together into a class, similar to BatchIter, that will do the iteration for us:
class GroupBatchIter:
def __init__(self, group_id, *tensors, batch_size=1, shuffle=True, shuffle_seed=42):
self.group_id = group_id
self.tensors = tensors
if shuffle:
self.idxs = lexsort(group_id, fnv_hash(group_id + seed))
else:
self.idxs = torch.arange(len(group_id), device=group_id.device)
group_start_indices = group_idx(group_id[self.idxs])
self.batch_start, self.batch_end = batch_endpoint_indices(group_start_indices, batch_size)
def __len__(self):
return len(self.batch_start)
def __iter__(self):
# we create mini-batches containing both group-id, and the additional
# tensors
tensors = (self.group_id,) + self.tensors
# iterate over batch endpoints, and yield tensors
for start, end in zip(self.batch_start, self.batch_end):
batch_idxs = self.idxs[start:end]
if len(batch_idxs) > 0:
yield tuple(x[batch_idxs, ...] for x in tensors)
Now let’s try it out. First, we generate some data, and use Pandas for pretty-printing:
import pandas as pd
group_id = torch.tensor([8, 8, 8, 1, 1, 7, 7, 7, 7])
features = torch.arange(len(group_id) * 3).reshape(len(group_id), 3)
labels = torch.arange(len(group_id)) % 2
print(pd.DataFrame.from_dict({
'group_id': group_id.tolist(),
'features': features.tolist(),
'labels': labels.tolist()
}))
group_id features labels
0 8 [0, 1, 2] 0
1 8 [3, 4, 5] 1
2 8 [6, 7, 8] 0
3 1 [9, 10, 11] 1
4 1 [12, 13, 14] 0
5 7 [15, 16, 17] 1
6 7 [18, 19, 20] 0
7 7 [21, 22, 23] 1
8 7 [24, 25, 26] 0
So we have three groups, and we are simulating some features of each sample, and binary labels. Now let’s try iterating with a batch size of two:
for gb, Xb, yb in GroupBatchIter(group_id, features, labels, batch_size=2, shuffle=True):
print(pd.DataFrame.from_dict({
'group_id': gb.tolist(),
'features': Xb.tolist(),
'labels': yb.tolist()
}))
group_id features labels
0 1 [9, 10, 11] 1
1 1 [12, 13, 14] 0
2 8 [0, 1, 2] 0
3 8 [3, 4, 5] 1
4 8 [6, 7, 8] 0
group_id features labels
0 7 [15, 16, 17] 1
1 7 [18, 19, 20] 0
2 7 [21, 22, 23] 1
3 7 [24, 25, 26] 0
Indeed we see that the order has been changed, so shuffling happened. The first batch contains the samples from groups 1 and 8 - two groups, as specified by the batch size. The second batch contains samples from the remaining group 7. We also note that the order among the samples in each group is preserved.
So what about speed? Let’s try it out. We already have samples and labels from the previous batch iteration code without groups. So let’s just generate a group-id tensor, with 8 samples in group on average:
n_groups = n_samples // 8
group_id, _ = torch.multinomial(torch.ones(n_groups) / n_groups, n_samples, replacement=True).sort()
print(group_id[:50]) # print the first 50 group IDs
tensor([0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 5, 5, 5, 5, 5, 5, 5, 6, 6, 6, 6,
6, 6])
Looks OK. Now let’s measure iteration speed with mini-batches of 64 groups:
%%time
for gb, Xb, yb in GroupBatchIter(group_id, X, y, batch_size=64, shuffle=True):
pass
CPU times: user 178 ms, sys: 20 ms, total: 198 ms
Wall time: 199 ms
That’s fast, and it appears we are done :)
Summary
We wrote two batch iteration utilities - one for iterating over individual samples, and another one for iterating over groups of samples. Both are useful for different settings, and I hope you will find them useful to accelerate your experiments on a small scale, before you reach a larger scale. It certainly made me more productive, especially when working on experiments for papers. And most importantly, if you have a better way of implementing these utilities - please let me know!
References
-
Fey, M., & Lenssen, J. E. (2019). Fast Graph Representation Learning with PyTorch Geometric [Computer software]. https://github.com/pyg-team/pytorch_geometric ↩