Paying attention to feature distribution alignment
This post is part of the series "Polynomial features in machine learning", and is not self-contained.
Series posts:
-
“Are polynomial features the root of all evil?"
-
“Keeping the polynomial monster under control"
-
“SkLearning with Bernstein Polynomials"
-
SkLearning with Bernstein Polynomials - continued
-
A Bernstein SkLearn model calibrator
-
Regularization properties of polynomial bases
-
Let the polynomial monster free
-
Off with the polynomial's tail!
- Paying attention to feature distribution alignment (this post)
- “Are polynomial features the root of all evil?"
- “Keeping the polynomial monster under control"
- “SkLearning with Bernstein Polynomials"
- SkLearning with Bernstein Polynomials - continued
- A Bernstein SkLearn model calibrator
- Regularization properties of polynomial bases
- Let the polynomial monster free
- Off with the polynomial's tail!
- Paying attention to feature distribution alignment (this post)
Intro
Yes, I’m making a joke of the tendency to put the words “attention” and “alignment” in any ML paper 😎. Now let’s see how this provocative title is related to our adventures in the land of polynomial features.
The Legendre polynomial basis serverd us well in recent posts about polynomial features. One interesting thing we saw in the series is that its orthogonality is, in some sense informativeness. This is because it orthogonal bases produce features, and hence each basis function, in some sense, carries information that the other basis functions do not. Of course, we all like informative features. So I’d like to devote this post to studying it a bit deeper.
But the Legendre basis is informative in this sense only if our features are uniformly distributed. But real data isn’t uniformly distributed. So in this post I’d like to discuss two ways in which can deal with this practical issue. The associated notebook for reproducing all results is here.
Orthogonality = informativeness
So that we all are on the same page, let’s recall why orthogonal bases produce uncorrelated features. Recall, the two polynomials \(P_i\) and \(P_j\) defined on \([-1, 1]\) are orthogonal if
\[\langle P_i, P_j \rangle = \int_{-1}^1 P_i(x) P_j(x) dx = 0,\]just like two orthogonal vectors - their inner product is zero. But here the inner product is an integral rather than a sum. But an integral is also an expectation, and empirical averages approximate expectations. So if our data points \(x_1, \dots, x_n\) are approximately uniform in \([-1, 1]\), then
\[0 = \int_{-1}^1 P_i(x) P_j(x) dx \sim \frac{2}{n} \sum_{k=1}^n P_i(x_k) P_j(x_k).\]Hence, any column in the data-set the model observes during training is uncorelated to the other columns coming from the same orthogonal basis, and thus in some sense carry information that the other columns do not have.
Informativeness, of course, is not the only important trait of a good basis for non-linear features. In fact, even the norms of the orthogonal basis are important, as well as other traits. I advise reading the well-written and enlightening paper1 by Muthukumar et. al for more on this. But here, in this post, we focus mainly on orthogonality as informativeness.
Weighted orthogonality
Going back to our linear algebra classes, inner products come in many forms. Given a vector of weights \(\mathbf{w} > 0\), we can define a weighted inner product:
\[\langle \mathbf{x}, \mathbf{y} \rangle_{\mathbf{w}} = \sum_{i=1}^n x_i y_i w_i.\]The contribution of every two components at index \(i\) is weighted by the weight \(w_i\).
Similarly, given a weight function \(w(x)>0\) integrable over the domain \(D\), we can define a weighted inner product between two functions on that domain:
\[\langle f, g\rangle_w = \int_{D} f(x)g(x)w(x)dx\]The contribution at each point \(x\) to the integral is weighted by the weight \(w(x)\). The Legendre basis, for example, is orthogonal on \(D = [-1, 1]\) according to the uniform weight \(w(x) = 1\).
Now let’s see what does it mean in terms of informativeness. Suppose without loss of generality that \(w(x)\) is normalized such that \(\int_{D} w(x) = 1\). If it’s not, we can always divide it by its integral. Now, it can be thought of as PDF of some probability distribution over \(x\), and therefore the inner product is just an expectation. Therefore if our data points \(x_1, \dots, x_n\) come from that distribution, then
\[\langle f, g \rangle_w = \mathbb{E}_x \left[ f(x) g(x) \right] \sim \frac{1}{n} \sum_{i=1}^n f(x_i) g(x_i).\]Consequently, if \(f\) and \(g\) are orthogonal w.r.t our inner product, the two features generated by \(f(x)\) and \(g(x)\) are uncorrlated, or informative.
So ideally we would like to devise orthogonal bases w.r.t the PDF of our data distribution. The differential equations community has been designing orthogonal bases w.r.t various weights for a long time, and have come up with plenty of methods and an enormous body of literature. But there are two extremely simple tricks we can adopt from them for ML, which I’d like to discuss in this pose. Both are also discussed in the context of approximation theory and differential equations in the recent survey paper by Shen and Wang2. One of them appears extremely intuitive, easy to implement, and is indeed useful in practice. The other one requires some careful math before coding, harder to apply in practice, and I’d like to present it and discuss when I believe it may be useful to.
The mapping trick
Let’s focus on the Legendre basis that is orthogonal on \([-1, 1]\). Instead of min-max scaling, which we did in previous posts, suppose we use some invertible and differentiable function \(\phi: D \to [-1, 1]\) that maps our feature from its original domain. In terms of the raw feature, our basis functions are
\[Q_i(x) = P_i(\phi(x)).\]Are they orthogonal? Well, in some sense, they are. Using the change of variable \(y = \phi(x)\), we know from high-school calculus that :
\[0 = \int_{-1}^1 P_i(y) P_j(y) dy = \int_{D} P_i(\phi(x)) P_j(\phi(x)) \phi'(x) dx = \langle Q_i, Q_j \rangle_{\phi'}\]The conclusion is simple - mapping with \(\phi\) results in orthogonal functions weighted by \(\phi'\). In particular, if \(\phi\) is a CDF of some distribution, then using the basis \(Q_0, Q_1, ...\) will result in uncorrelated features!
So what mapping should we use? If we know or can estimate the CDF \(W\) of our feature, we should use
\[x \to 2W(x) - 1.\]Indeed, it maps to \([-1, 1]\), and the derivative of this mapping is twice the PDF. Just what we need.
We can, of course, attempt to do mathematical acrobatics to extend this to non-differentiable CDF functions \(W\), but this is not a paper, just a blog post. In fact, we will use a non-differentiable CDF in our code, without doing the math. This idea aligns with our intuition at the intro - mapping using a “uniformizing” transformation before computing Legendre polynomials produces an orthogonal basis w.r.t the original raw feature.
A small simulation
We shall sample data from some distributions, and use the above mapping to transform it before computing the Legendre vandermonde matrix. Then, we shall inspect the correlation between columns. Here is a function that accepts a scipy.stats distribution object, and computes the correlation matrix:
import numpy as np
def simulate_correlation(dist, degree=20, n_samples=10000):
samples = dist.rvs(size=n_samples)
mapped = 2 * dist.cdf(samples) - 1
vander = np.polynomial.legendre.legvander(mapped)
return np.corrcoef(vander.T)
Pretty straightforward - sample, transform, compute Legenre basis functions for each mapped sample, and then correlation between any two resulting features. So let’s try doing some plots. Here is a simulation of our data having the standard Normal distirbution:
import matplotlib.pyplot as plt
import scipy.stats
plt.imshow(simulate_correlation(scipy.stats.norm(0, 1)))
plt.colorbar()
plt.show()
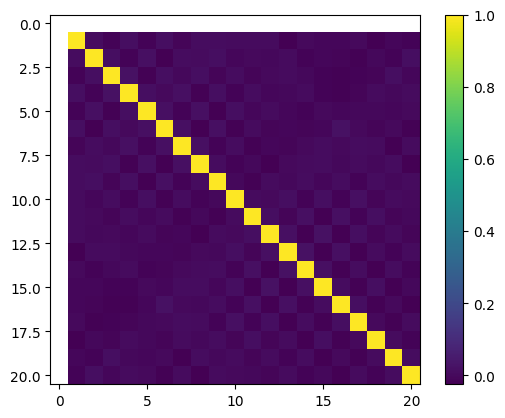
We see a diagonal of ones, and values close to zero outside the diagonal. Well, except for the first row and column - their are the constant function 1, so it has no variance, and thus no covariance. But that’s OK - in models we typically have a separate bias term, and do not include the constant function in our basis.
What about some non-standard normal?
plt.imshow(simulate_correlation(scipy.stats.norm(-5, 10)))
plt.colorbar()
plt.show()
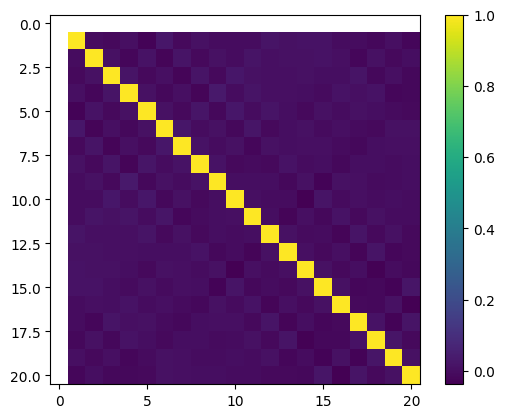
Similar - pairs of features are practically uncorrelated. Their correlation is close to zero. How about some Gamma distribution?
plt.imshow(simulate_correlation(scipy.stats.gamma(8, 2)))
plt.colorbar()
plt.show()
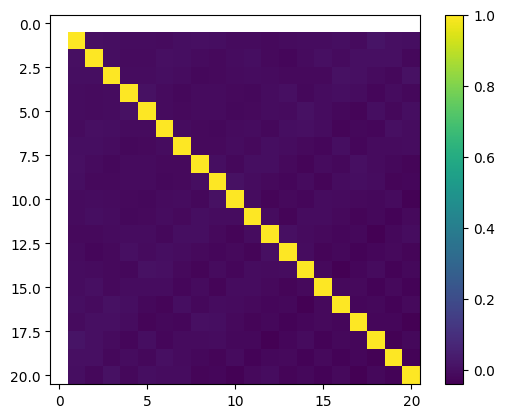
Neat! So if we know our data distribution, we can generate informative non-linear features by composing our CDF-based mapping with the Legendre basis.
The mapping trick in practice?
In practice we don’t know the data distribution of each column. We can estimate it by various means, such as fitting to some candidate distributions using SciPy. But we can also do another neat approximation - we can use Scikit-Learn’s QuantileTransformer, and it does approximately what we desire. It approximates the CDF, and maps raw features to quantiles using the CDF. We will just have to add one small step to map it from \([0, 1]\) to \([-1, 1]\). Note, that its approximate CDF is non-differentiable - it’s a step function. We haven’t shown anything for a non-differentiable CDF used as a mapping. This is where theory is just a good guide.
Here is a simple pipeline for fitting a linear regression model onto our orthogonal Legendre features, using our previously developed LegendreScalarPolynomialFeatures from the last post. This class doesn’t do anything special - just takes raw feature columns, and computes the Legendre vandermonde matrix.
from sklearn.preprocessing import QuantileTransformer, FunctionTransformer
from sklearn.pipeline import Pipeline
def ortho_features_pipeline(degree=8):
return Pipeline([
('quantile-transformer', QuantileTransformer()),
('post-mapper', FunctionTransformer(lambda x: 2*x - 1)),
('polyfeats', LegendreScalarPolynomialFeatures(degree=degree)),
])
Let’s try applying it to some simulated data and see if we get uncorrelated features. We shall generate two data columns with a Normal and a Gamma distribution, compute features using our pipeline, and plot their correlation matrix:
# two columns - Normal and Gamma
sim_data = np.concatenate([
scipy.stats.norm(-5, 3).rvs(size=(1000, 1)),
scipy.stats.gamma(8, 2).rvs(size=(1000, 1)),
], axis=1)
# features
features = ortho_features_pipeline().fit_transform(sim_data)
# plot correlation matrix
coef_mat = np.corrcoef(features.T)
plt.imshow(coef_mat)
plt.colorbar()
plt.show()
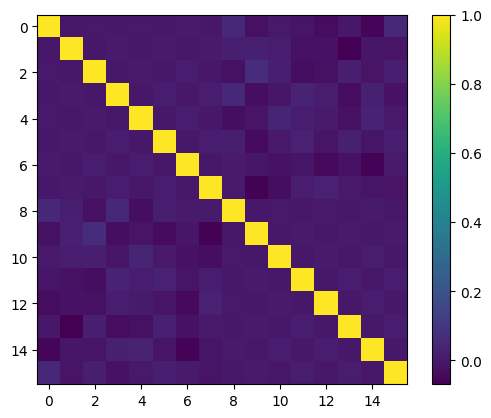
Nice! Now let’s try training a linear regression model with our new pipeline.
Testing on real data
Let’s load our beloved california housing dataset and see what we have achieved. Let’s load it, and apply the log transformation we always do to the skewed columns:
import pandas as pd
train_df = pd.read_csv("sample_data/california_housing_train.csv")
test_df = pd.read_csv("sample_data/california_housing_test.csv")
X_train = train_df.drop("median_house_value", axis=1)
y_train = train_df["median_house_value"]
X_test = test_df.drop("median_house_value", axis=1)
y_test = test_df["median_house_value"]
skewed_columns = ['total_rooms', 'total_bedrooms', 'population', 'households']
X_train.loc[:, skewed_columns] = X_train[skewed_columns].apply(np.log)
X_test.loc[:, skewed_columns] = X_test[skewed_columns].apply(np.log)
Now let’s fit a linear regression model and see that it works:
from sklearn.linear_model import LinearRegression
from sklearn.metrics import root_mean_squared_error
pipeline = Pipeline([
('ortho-features', ortho_features_pipeline()),
('lin-reg', LinearRegression()),
])
pipeline.fit(X_train, y_train)
root_mean_squared_error(y_test, pipeline.predict(X_test))
62672.703496184964
Let’s compare to our min-max scaling strategy we tried in previous posts:
from sklearn.preprocessing import MinMaxScaler
def minmax_legendre_features(degree=8):
return Pipeline([
('scaler', MinMaxScaler(feature_range=(-1, 1), clip=True)),
('polyfeats', LegendreScalarPolynomialFeatures(degree=degree)),
])
pipeline = Pipeline([
('minmax-legendre', minmax_legendre_features()),
('lin-reg', LinearRegression()),
])
pipeline.fit(X_train, y_train)
root_mean_squared_error(y_test, pipeline.predict(X_test))
63426.15965332127
So at least for the default Legendre polynomial degree, the approximately orthogonal features appear to work quite well. What Let’s try to compare several degrees:
for deg in range(1, 22, 2):
pipeline = Pipeline([
('minmax-legendre', minmax_legendre_features(degree=deg)),
('lin-reg', LinearRegression()),
])
pipeline.fit(X_train, y_train)
minmax_rmse = root_mean_squared_error(y_test, pipeline.predict(X_test))
pipeline = Pipeline([
('ortho-features', ortho_features_pipeline(degree=deg)),
('lin-reg', LinearRegression()),
])
pipeline.fit(X_train, y_train)
ortho_rmse = root_mean_squared_error(y_test, pipeline.predict(X_test))
print(f'Degree = {deg}, minmax_rmse = {minmax_rmse:.2f}, ortho_rmse = {ortho_rmse:.2f}')
The output is:
Degree = 1, minmax_rmse = 67775.24, ortho_rmse = 74588.32
Degree = 3, minmax_rmse = 65137.16, ortho_rmse = 67551.46
Degree = 5, minmax_rmse = 64054.74, ortho_rmse = 65010.42
Degree = 7, minmax_rmse = 63523.41, ortho_rmse = 63297.67
Degree = 9, minmax_rmse = 63440.02, ortho_rmse = 61606.44
Degree = 11, minmax_rmse = 63305.14, ortho_rmse = 61438.60
Degree = 13, minmax_rmse = 65575.86, ortho_rmse = 61237.12
Degree = 15, minmax_rmse = 175047.47, ortho_rmse = 60611.78
Degree = 17, minmax_rmse = 175270.39, ortho_rmse = 60680.52
Degree = 19, minmax_rmse = 781416.93, ortho_rmse = 60111.46
At least on this dataset, the truly orthogonal features appear to be better. Note, how the error of the naively-scaled basis rapidly increases - we’re losing informativeness. Of course, we know that if we crank-up the degree to 10,000, we will observe double descent, and all the other nice stuff we saw in previous posts. But that’s not the point of this post.
What about Ridge regression? Maybe it’s somewhat different? It should be - regularization should “tame” the behavior of the min-max scaled features. But are the orghogonal features still better?
from sklearn.linear_model import RidgeCV
for deg in range(1, 22, 2):
pipeline = Pipeline([
('minmax-legendre', minmax_legendre_features(degree=deg)),
('lin-reg', RidgeCV()),
])
pipeline.fit(X_train, y_train)
minmax_rmse = root_mean_squared_error(y_test, pipeline.predict(X_test))
pipeline = Pipeline([
('ortho-features', ortho_features_pipeline(degree=deg)),
('lin-reg', RidgeCV()),
])
pipeline.fit(X_train, y_train)
ortho_rmse = root_mean_squared_error(y_test, pipeline.predict(X_test))
print(f'Degree = {deg}, minmax_rmse = {minmax_rmse:.2f}, ortho_rmse = {ortho_rmse:.2f}')
The output is
Degree = 1, minmax_rmse = 67771.06, ortho_rmse = 74482.30
Degree = 3, minmax_rmse = 65121.63, ortho_rmse = 67485.67
Degree = 5, minmax_rmse = 64077.37, ortho_rmse = 64971.80
Degree = 7, minmax_rmse = 63541.46, ortho_rmse = 63380.61
Degree = 9, minmax_rmse = 63394.64, ortho_rmse = 61650.67
Degree = 11, minmax_rmse = 62889.19, ortho_rmse = 61386.24
Degree = 13, minmax_rmse = 62305.72, ortho_rmse = 61192.17
Degree = 15, minmax_rmse = 62276.36, ortho_rmse = 60649.21
Degree = 17, minmax_rmse = 62045.29, ortho_rmse = 60677.81
Degree = 19, minmax_rmse = 61883.94, ortho_rmse = 60165.78
Degree = 21, minmax_rmse = 61802.18, ortho_rmse = 59526.32
It appears they are. Except for the initial low-degree polynomials, the orthogonal features we obtained by composing the the (empirical) CDF appear to outperform naive min-max scaling.
Obviously, in practice the degree is a tunable parameter. Its performance should be tested on a validation set, and the best configuraion should then be employed on the test set for a final evaluation. But if the same phenomenon happens across many degrees, then I believe it’s convincing enough.
This is not a paper, and this is not a thorough benchmark on a variety of data-sets. This is not the point - the point is that even though data speak, theory guides. And its guidance can be oftentimes useful, if you listen carefully.
The multiplication by one trick
Many deep results in mathematics are derived by multiplying by one, but this one has to be chosen wisely. So let’s choose our one wisely. We have:
\[f(x) g(x) w(x) = \frac{f(x)}{u(x)} \frac{g(x)}{u(x)} w(x) u^2(x)\]This looks a bit hairy, but all we did was multiply and divide by \(u(x) \neq 0\). Consequently, if \(\langle f, g \rangle_w = 0\), then
\[\left\langle \frac{f}{u}, \frac{g}{u} \right \rangle_{w u^2} = 0.\]So taking a basis \(Q_0, Q_1, \dots\) orthogonal w.r.t \(w\), and dividing all functions by a given non-zero function \(u(x)\), we obtain a basis orthogonal w.r.t a new weight \(wu^2\). This reminds the well-known importance sampling Monte-Carlo algorithms, where we can choose a more convenient distribution to sample from by multiplying and dividing by a well-chosen density.
We can choose the weight we desire by carefully choosing \(u\), right? Easy peasy - just divide all functions by \(u\), and we’re done! But it’s not that simple, because the new basis
\[\frac{Q_0}{u}, \frac{Q_1}{u}, \dots\]might have a radically different representation power. Especially if we take only a finite number of basis functions, like we do in machine learning.
For example, if our original basis was bounded, but the ratio \(\frac{1}{u(x)}\) isn’t, then the new basis suddenly consists of unbounded functions that may grow to infinity. Alternatively, if this ratio decays towards zero, then the new basis functions also decay towards zero.
Let’s look at a concrete case to understand the issue. Suppose our feature \(x\) is the total time the user spent on our website in the last month. Probably, the effect of this feature on user behavior “flattens” at some point - users who spent 5 minutes may be different than the ones that spent 10 minutes, but those that spent 10 hours may not be that different from those that spent 20. We certainly would not want a function that grows to infinity as \(x\) grows!
The other side of our observation is that this idea of dividing by \(u\) gives us some degree of control. You can mix it with the mapping approach to design a family of feature orthogonal w.r.t the weight of your choice, but also have the desired properties you want, such as growth or decay. These desired properties are the inductive bias you bake into your model to help it generalize better to unseen data, or conform to some regulatory or safety constraints.
This mixing and matching sounds easy, but it may not be so. Let’s look at an example, just to give you the feeling. Suppose our total time on the website has a distribution with CDF \(U\), and we want features that decay towards zero, because the effect of this total time eventually flattens out. If we take some mapping \(T: [0, \infty) \to [-1, 1]\), we can construct a basis from Legendre polynomials:
\[P_0(T(x)), P_1(T(x)), P_2(T(x)), ...\]This basis will be orthogonal w.r.t the weight \(T'(x)\), according to what we saw about the mapping trick. Now, to make these functions decay towards zero, we may want to divide them by some unbounded function, such as \(u(x)=1 + x\), and get a new basis:
\[\underbrace{\frac{P_0(T(x))}{1+x}}_{Q_0(x)}, \underbrace{\frac{P_1(T(x))}{1+x}}_{Q_1(x)}, ...\]According to what we saw now, \(Q_0, Q_1, ...\) is orthogonal w.r.t the weight function \(w(x) = T'(x) (1 + x)^2\).
So now, we want to design the mapping \(T\) such that the weight aligns with the data distribution, to get informative features from our basis. This means we want the weight to be proportional to the PDF: \(T'(x) (1 + x^2) = a U'(x), \qquad a > 0.\)
Equivalently
\[T(x) = a\int \frac{U'(x)}{1+x^2}dx + b.\]Here, we will chose such that \(T\) maps to the interval \([-1, 1]\). This ensures that our features are both orthogonal w.r.t the right weight function, the PDF of the data distribution, and also decay towards zero, because we divided bounded Legendre polynomials by \(u(x) = 1 + x\). Of course, there may be many decay inducing functions, such as \(u(x)=\exp(x)\). This is where your “feature engineering” voodoo kicks in.
But now we saw why this approach is less useful in practice - complexity. It’s hard to choose the “right” decay function. You’ll also have to estimate some distribution \(U\) from the data, and then compute an integral. Maybe this \(U\) is just a non-differentiable empirical CDF - and you’ll need to do some acrobatics to deal with it. And of course you’ll have to know the lower and upper bound on the integral, so that you can chose \(a\) and \(b\).
I haven’t done all this math, so I don’t know the extent to which all of these are easily solvable. But it seems like a lot of trouble! Definitely not something we’re used to doing at work, and much harder than just stacking a QuantileTransformer before your favorite orthogonal polynomial basis. Thus, unless you’re absolutely sure you have to build these inductive biases into your model, i.e. safety or regulations, then I wouldn’t go in this direction. But I hope you appreciate the fact that you can actually do it with enough effort.
Of course, because of this complexity, conducting an experiment on our data-set is out of the scope of this post, and I’ll leave this part as is - just theoretical.
Summary
Now it appears clear why the provocative title fits this post - we indeed paid close attention to the alignment between our non-linear features and the data distribution. This alignment is manifested in the form of the weight of the inner-product space our basis functions live in. I will repeat myself here as well - data speaks, but theory guides, if you care to listen.
Note, that the differential equations community puts a different emphasis on these orthogonal bases. The weight function plays a different role, and the “inductive bias” we talked about in the multiplication trick is less relevant - they care about approximation power, and less about inductive biases. Both are related, but not exactly the same. So reading the paper by Shen and Wang may be interesting, but focuses on different things.
References
-
Muthukumar, V., Vodrahalli, K., Subramanian, V. and Sahai, A., 2019. Harmless interpolation of noisy data in regression. arXiv preprint arXiv:1903.09139. ↩
-
Shen, J. and Wang, L.L., 2009. Some recent advances on spectral methods for unbounded domains. Communications in computational physics, 5(2-4), pp.195-241. ↩